Athena란?
AWS S3에 보관된 데이터를 SQL을 사용하여 분석할 수 있는 서비스
사용하게 된 계기
처음 프로젝트에서 분석할 데이터를 DynamoDB에 보관을 하는데 집계를 하기가 너무 불편해서
우울하던 중에 AWS 페북 그룹에서 Vingle이라는 회사에서 당시 세션 제목은 잘 기억 안 나는데
로그 였나.. 사용자 패턴이였나.. 아무튼 나에게 필요한 정보를 배울 수 있을 거 같아서 퇴근하고
참가 했었다 설명을 듣고 다음 프로젝트에는 꼭 써보기로 마음을 먹었었다 ☺️
사용하면서 느꼈던 장점
- 별도로 설치나 버전 관리 등을 할 일이 없어서 편리 했었다.
- 쿼리 사용 회수량에 따른 요금 부과
사용하면서 느꼈던 단점
- 아래에 기술하겠지만 파티션을 불러와야 하는데 일일 기준으로 파티셔닝을 하면 하루에 한번씩 로드를 해줘야 한다. 자동 지원이 아니였음 (혹시 자동 지원 하는 방법을 내가 몰랐을지도 모른다)
- 데이터를 분석하는 사람이 SQL을 모르면 음..
Athena 실습 해보기
임시 데이터
Athena의 비용을 절감하기 위해서는 gzip 압축 하는 게 좋다고 한다.
데이터가 적은 json은 상관없지만 json이 규모가 큰 경우에는 고려해야 한다.
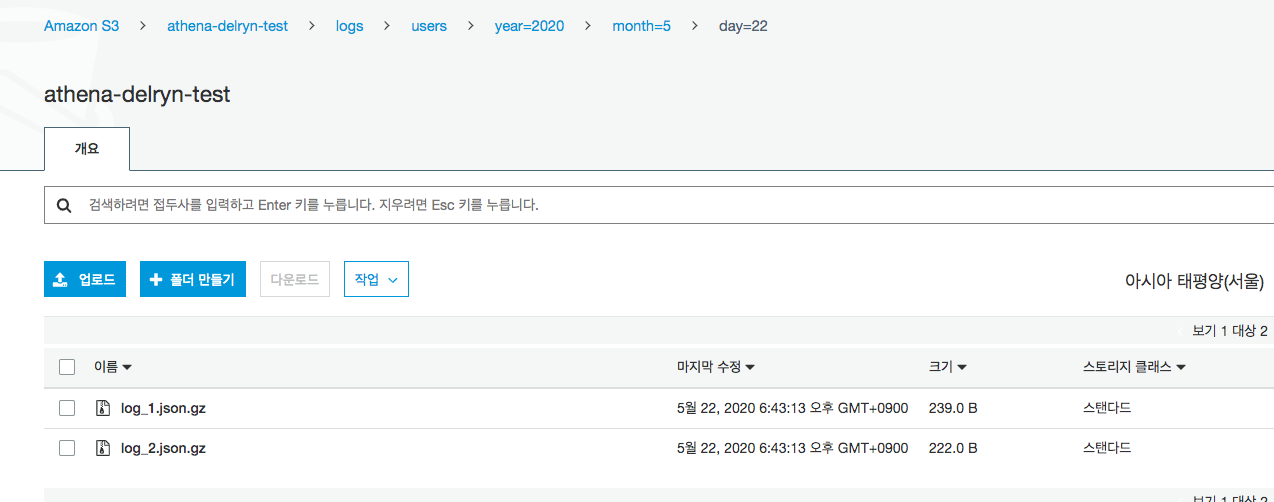
지금은 json 데이터를 압축해서 S3에 업로드 해 본다.
1 | const obj = { |
1 | const fs = require('fs'); |
NOTE
- s3에 json pretty 파일을 업로드를 하게 되는 경우 나중에 쿼리할 때 json 파싱 쪽 오류가 난다.
- s3 prefix를 확인해 둘 것. (이후 파티셔닝 때문에)
Workgroup 생성
이제 athena 메뉴로 가서 Workgroup을 생성 하고 내용은 상황에 맞게 적어주자.
Workgroup을 만드는 이유는 분류별로 쿼리의 결과를 저장할 s3를 지정 해주는 것
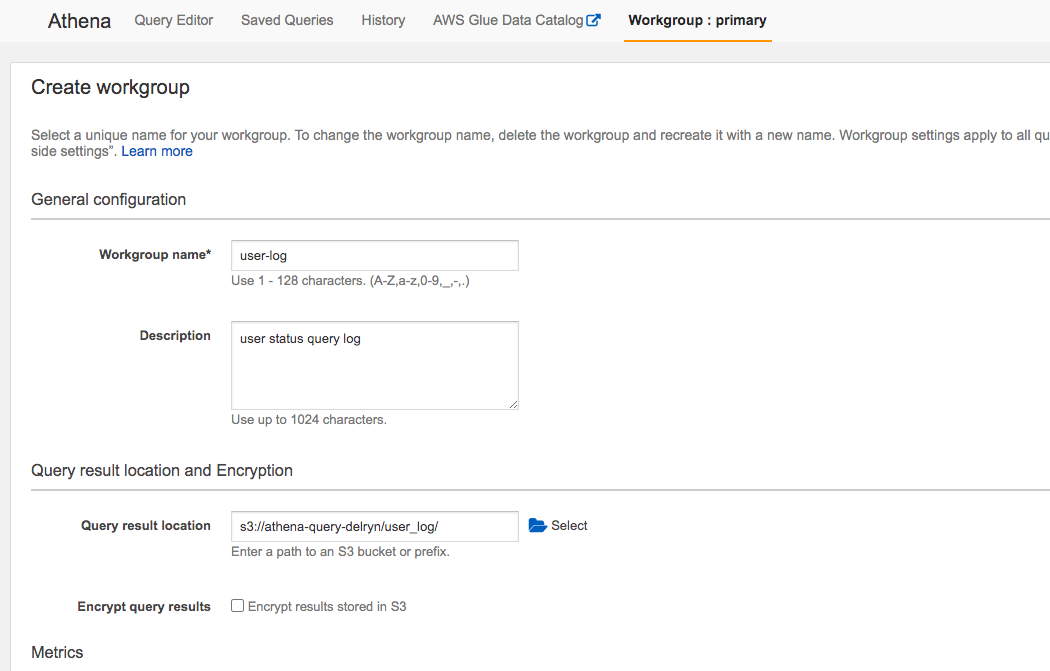
생성 하면 default로 primary가 되어 있기 때문에 이번에 생성한 걸로 바꿔 준다.
데이터베이스 생성
1 | CREATE DATABASE log_db |

테이블 생성
내가 만든 데이터베이스를 선택 하고 테이블을 생성 한다.
1 | CREATE EXTERNAL TABLE user_log ( |
- 테이블의 필드는 json의 키, 데이터 타입은 링크에서 확인
- PARTITIONED을 거는 이유는 s3에서 쿼리 시 모든 파일을 스캔 하기 떄문에 비용이 많이 들고 쿼리 응답 지연 시간이 늘어나기 때문에 지정을 해줘야 비용, 성능 상으로 모두 좋다.
- ROW FORMAT SERDE은 그냥 json 데이터니 json 라이브러리 추가
- LOCATION은 분석할 데이터가 보관되어 있는 s3 경로

파티션 로드
1 | MSCK REPAIR TABLE user_log; |
위에서 적은 단점이 이 부분인데 좀 더 자세하게 예로 들자면
현재 일일별로 파티션을 걸어놨기 때문에 오늘(5월 22일) 파티션 로드 시 s3에 22일에 업로드된
데이터들(로드 이후에도 업로드 되는 데이터까지) 쿼리가 가능 하다.
그러나 다음 날(23일)에 s3에 데이터가 업로드 되고 파티션 로드를 안한 상태에서는
22일자 데이터로만 쿼리가 가능 해서 파티션 로드를 당일 다시 해줘야 23일자 데이터도 쿼리로
읽을 수 있다 그러므로 일일별로 하루에 한번 파티션 로드를 해줘야 한다.
1 | ALTER TABLE user_log ADD PARTITION (year = 년, month = 월, day = 일) LOCATION 's3://athena-delryn-test/logs/users/' |
나는 일일 00시 지나가고 나서 Lambda CloudWatchEvent로 cron을 돌렸었다.
쿼리 실행
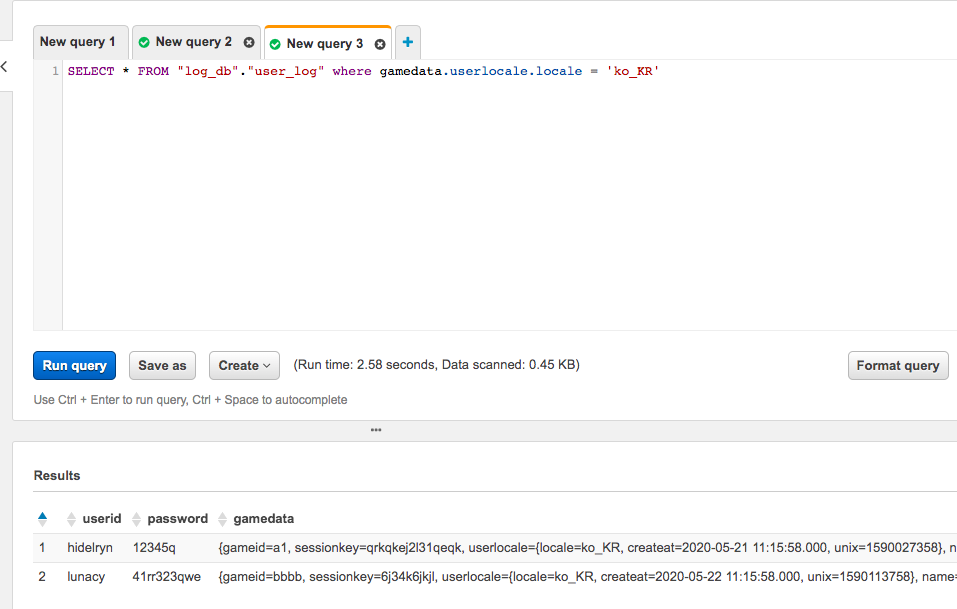
결과를 볼 수 있게 쿼리를 실행 해 본다.
1 | SELECT * FROM "log_db"."user_log" where gamedata.userlocale.locale = 'ko_KR'; |